【Python爬虫实例学习篇】——1、获取拉勾网职位信息
毕业季就要到了,打算上拉钩网爬一下有关实习岗位的招聘信息。刚写完几行代码进行调试发现一直提示:
{“status”:false,”msg”== :”您操作太频繁,请稍后再访问”,”clientIp”:”223.155.85.177”,”state”:2402},此时进入网页一看,能够正常进行访问,并没有出现上述提示语,据此判断存在反爬虫机制。经过一番尝试发现是cookie的问题,下面是解决问题的详细过程。
问题
一开始想用urllib库来获取招聘信息结果发现返回结果一直是操作频繁,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| from urllib import request,parse
KeyWord="python"
url="https://www.lagou.com/jobs/list_"+KeyWord+"?&cl=false&fromSearch=true&labelWords=&suginput="
url_GetJob="https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36",
"Referer":url
}
data={
"first":"true",
"pn":"1",
"kd":KeyWord
}
req=request.Request(url_GetJob,headers=headers,data=parse.urlencode(data).encode('utf-8'))
response=request.urlopen(req)
print(response.read().decode('utf-8'))
|
返回结果为:

此时网页直接访问情况:
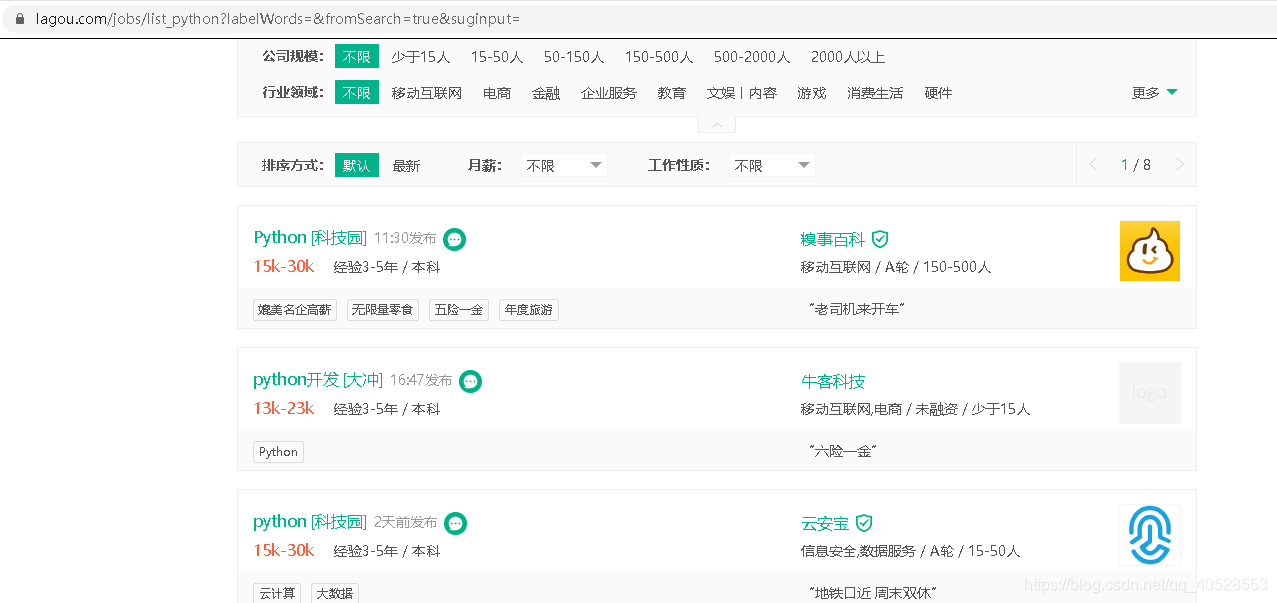
解决办法
方法1:利用http.cookiejar
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| from urllib import request, parse
import http.cookiejar
KeyWord = "python"
url = "https://www.lagou.com/jobs/list_" + KeyWord + "?&cl=false&fromSearch=true&labelWords=&suginput="
url_GetJob = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36",
"Referer": url
}
data = {
"first": "true",
"pn": "1",
"kd": KeyWord
}
cookie_jar = http.cookiejar.CookieJar()
handler = request.HTTPCookieProcessor(cookie_jar)
opener = request.build_opener(handler)
req = request.Request(url, headers=headers)
opener.open(req)
req2=request.Request(url_GetJob,headers=headers, data=parse.urlencode(data).encode('utf-8'))
res = opener.open(req2)
print(res.read().decode('utf-8'))
|
方法2:利用requests.session
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import requests
KeyWord = "python"
url = "https://www.lagou.com/jobs/list_" + KeyWord + "?&cl=false&fromSearch=true&labelWords=&suginput="
url_GetJob = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36",
"Referer": url
}
session = requests.session()
res1 = session.get(url, headers=headers, verify=False)
data = {
"first": "true",
"pn": "1",
"kd": KeyWord
}
res = session.post(url_GetJob, headers=headers, data=data, verify=False)
|
结果
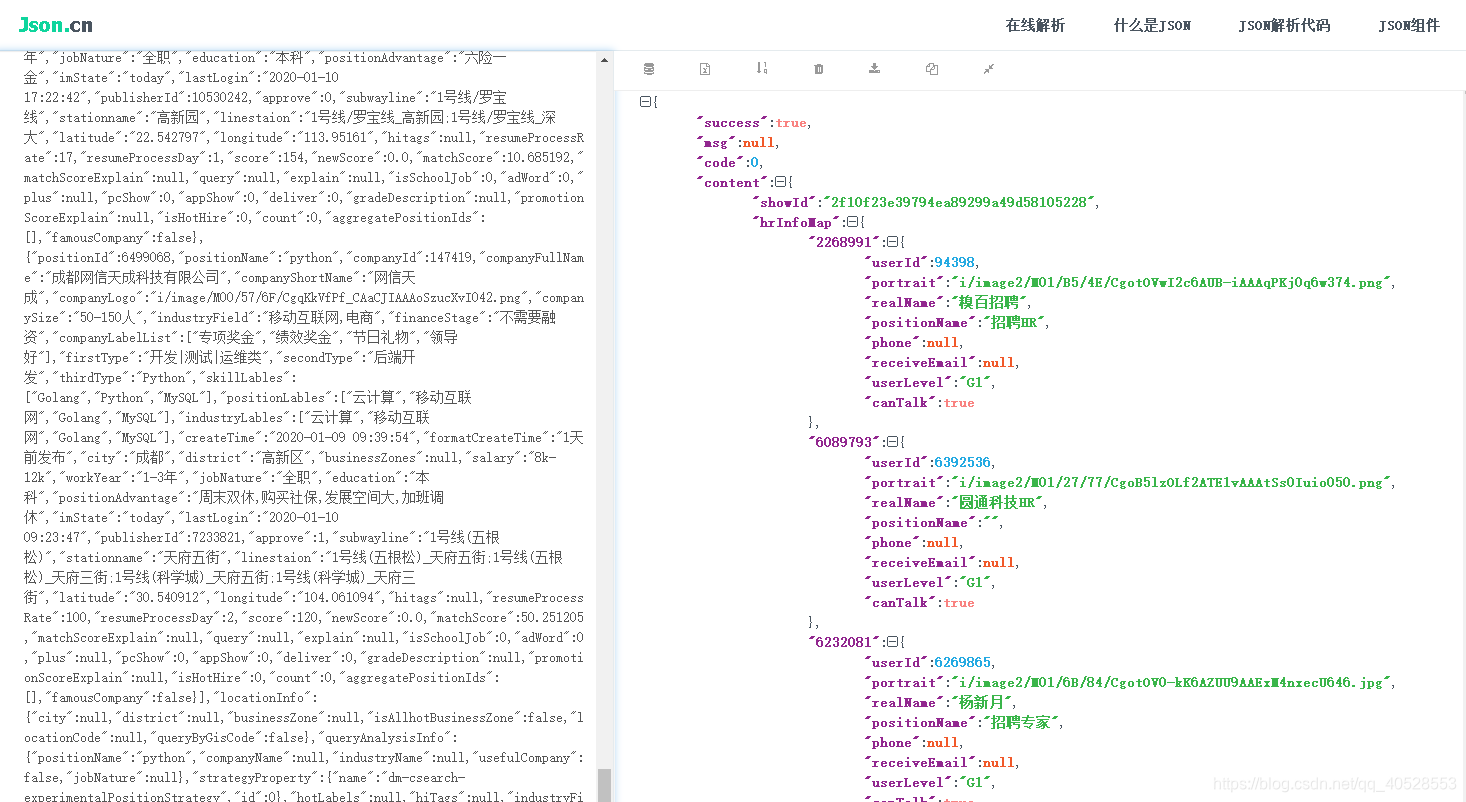
==微信公众号:==


