【Python爬虫实例学习篇】——3、访问CSDN并编译成exe文件
==首先声明:本博文仅供技术参考,想要提高访问量,好的博文才是王道!!!==
用到的工具:
- Python 3.6
- requests库
- request库(为什么会有两个???因为我只是单纯想练练手哈哈)
- random库
- time库
- pyinstaller库(用于生成exe文件)
目录:
- 代理库的构建(GetFreeProxies.py)
- 获取所有文章的链接
- 访问文章
- CSDNVisit.py
- 编译
- 结果展示
代理库的构建
详情请看【Python爬虫实例学习篇】——2、获取免费IP代理。
获取所有文章的链接
思路:访问主页,然后用xpath语法获取所有文章的链接
1
2
3
4
5
6
| def GetUrlList(homeurl):
res = request.urlopen(url=homeurl)
html = etree.HTML(res.read().decode('utf-8'))
UrlList = html.xpath('//h4//a/@href')
return UrlList
|
访问文章
由于CSDN在记录阅读数时会检查IP地址,而又由于免费代理不稳定,可能存在超时等问题,故需要使用try和except来避免错误中断。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| def GetUrlList(homeurl):
res = request.urlopen(url=homeurl)
html = etree.HTML(res.read().decode('utf-8'))
UrlList = html.xpath('//h4//a/@href')
return UrlList
def Visit(homeurl, method, UrlList, num, IP_list):
user_agent_list = [
{'Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0)'},
{'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)'},
{'Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)'},
{'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11'},
{'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1'}
]
success = 0
fail = 0
i=0
while num>success:
i=i+1
headers = {
'User-Agent': str(choice(user_agent_list)),
'Referer': homeurl
}
if len(IP_list):
ip = IP_list[0].strip('\n')
IP_list.remove(IP_list[0])
else:
if method == 1:
IP_list = GetFreeProxies.GetFreeProxy()
elif method == 2:
IP_list = GetFreeProxies.GetFreeProxyList()
elif method == 3:
IP_list = GetFreeProxies.GetFreeProxyAPI()
elif method == 4:
IP_list = GetFreeProxies.GetFreeProxyListAPI()
else:
print("暂未设置更多方法!")
return 0
print('-' * 45)
print("| 序号:" + str(i)+' |')
for j in range(len(UrlList)):
print('当前正在浏览第' + str(j) + '篇文章,链接:' + UrlList[j])
url = str(UrlList[j])
proxy_dict = {'https': ip}
handler = request.ProxyHandler(proxies=proxy_dict)
opener = request.build_opener(handler)
req = request.Request(url=url, headers=headers)
try:
res = opener.open(req, timeout=10).read().decode('utf-8')
html = etree.HTML(res)
VisitCount = html.xpath("//div/span[@class='read-count']")
sleepnum = random() * 4 + 1
print(str(VisitCount[0].text) + " || " + "随机延迟:" + "%2.f" % sleepnum + "|| 代理IP为:" + ip)
success=success+1
sleep(sleepnum)
except Exception:
sleepnum = random() * 2
print('代理IP:' + ip + '连接失败! ' + '||' + ' 随机延迟:' + "%2.f" % sleepnum)
fail=fail+1
sleep(sleepnum)
break
print('成功数:%i' % success + ' 失败数:%i' % fail + ' || 连接数:%i' % (success + fail)+' || 剩余任务数:%i' %(num-success))
|
CSDNVisit.py
说明:
博客主页:如 https://blog.csdn.net/qq_40528553
阅读次数:如 5000
代理方法: 如 2
- 方法1,代表直接访问网页获取1个代理ip
- 方法2,代表直接访问网页获取15个代理ip,推荐使用,成功率超50%
- 方法3,代表使用API一次获取1个代理ip
- 方法4,代表使用API一次获取15个代理ip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
| from urllib import request
from random import choice, random
from time import sleep
from lxml import etree
import GetFreeProxies
def VisitCsdn(homeurl, num=1, method=4):
if method == 1:
IP_list = GetFreeProxies.GetFreeProxy()
elif method == 2:
IP_list = GetFreeProxies.GetFreeProxyList()
elif method == 3:
IP_list = GetFreeProxies.GetFreeProxyAPI()
elif method == 4:
IP_list = GetFreeProxies.GetFreeProxyListAPI()
else:
print("暂未设置更多方法!")
return 0
UrlList = GetUrlList(homeurl)
Visit(homeurl,method, UrlList, num, IP_list)
def GetUrlList(homeurl):
res = request.urlopen(url=homeurl)
html = etree.HTML(res.read().decode('utf-8'))
UrlList = html.xpath('//h4//a/@href')
return UrlList
def Visit(homeurl, method, UrlList, num, IP_list):
user_agent_list = [
{'Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0)'},
{'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)'},
{'Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)'},
{'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11'},
{'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1'}
]
success = 0
fail = 0
i=0
while num>success:
i=i+1
headers = {
'User-Agent': str(choice(user_agent_list)),
'Referer': homeurl
}
if len(IP_list):
ip = IP_list[0].strip('\n')
IP_list.remove(IP_list[0])
else:
if method == 1:
IP_list = GetFreeProxies.GetFreeProxy()
elif method == 2:
IP_list = GetFreeProxies.GetFreeProxyList()
elif method == 3:
IP_list = GetFreeProxies.GetFreeProxyAPI()
elif method == 4:
IP_list = GetFreeProxies.GetFreeProxyListAPI()
else:
print("暂未设置更多方法!")
return 0
print('-' * 45)
print("| 序号:" + str(i)+' |')
for j in range(len(UrlList)):
print('当前正在浏览第' + str(j) + '篇文章,链接:' + UrlList[j])
url = str(UrlList[j])
proxy_dict = {'https': ip}
handler = request.ProxyHandler(proxies=proxy_dict)
opener = request.build_opener(handler)
req = request.Request(url=url, headers=headers)
try:
res = opener.open(req, timeout=10).read().decode('utf-8')
html = etree.HTML(res)
VisitCount = html.xpath("//div/span[@class='read-count']")
sleepnum = random() * 4 + 1
print(str(VisitCount[0].text) + " || " + "随机延迟:" + "%2.f" % sleepnum + "|| 代理IP为:" + ip)
success=success+1
sleep(sleepnum)
except Exception:
sleepnum = random() * 2
print('代理IP:' + ip + '连接失败! ' + '||' + ' 随机延迟:' + "%2.f" % sleepnum)
fail=fail+1
sleep(sleepnum)
break
print('成功数:%i' % success + ' 失败数:%i' % fail + ' || 连接数:%i' % (success + fail)+' || 剩余任务数:%i' %(num-success))
if __name__ == '__main__':
print('*'*45)
print('* CSDN刷阅读量工具正式版 V1.0\t *')
print('* -by asyu17\t *')
print('* 2020/1/14\t *')
print('*'*45)
homeurl = input('请输入博客主页:')
num = input('请输入阅读次数:')
method = input('请选择代理方法:')
VisitCsdn(homeurl, int(num), method=int(method))
|
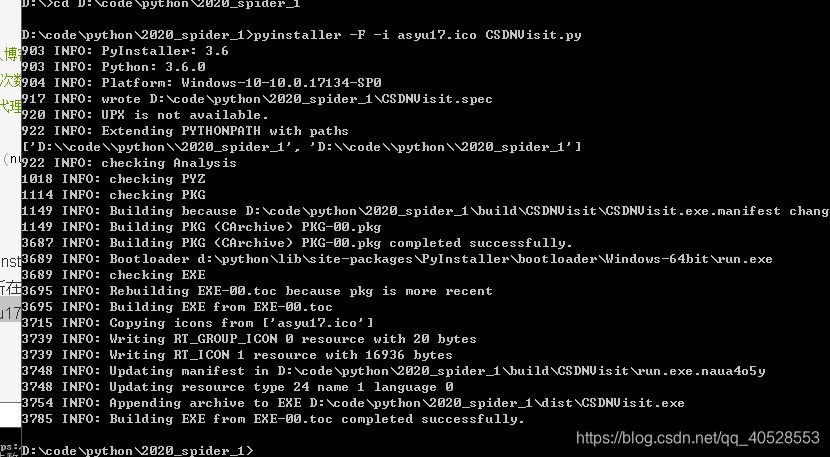
编译
- pip install pyinstaller 安装pyinstaller库
- 在cmd中定位到python脚本所在目录 如 cd D:\code\python\2020_spider_1
- 随后执行 pyinstaller -F -i asyu17.ico CSDNVisit.py 即可
- 可执行文件在dist目录中
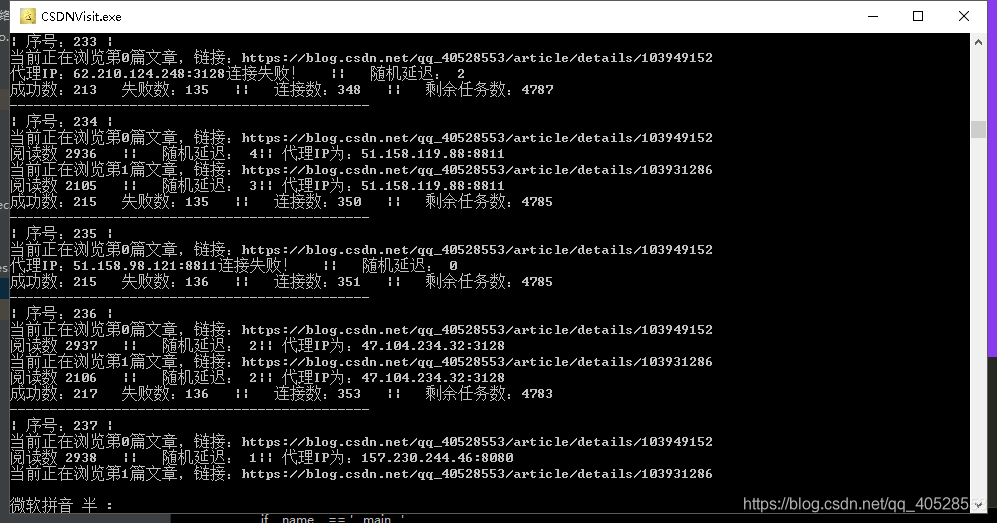
6、结果展示:
==微信公众号:==


